斜率优化
P3195 [HNOI2008] 玩具装箱
考虑 dp,令 , 为 到 $ i$ 装箱的最小代价,则转移方程为 。
此时,为了方便,我们将所有的 加 ,将 也加 ,那么式子简化为 。
此时,假设有 且由 转移更优,则 ,即 ,由于显然 ,令 ,因此 。
莫队是由集训队大佬莫涛提出来的,在此再次膜拜大佬!
普通莫队主要用于离线的区间查询操作,当然,也不是所有的都适用,当一个区间 的答案可以用 的时间转化成 的答案,我们就可以考虑使用莫队。
具体怎么做呢?其实就是将当前区间的答案通过一次一次移动 变成另一个区间的答案。
然后就没有了?
当然不是,这样很容易就被卡了,怎么卡呢,只需要将一次询问放在最前,下一次有放在最后,如此循环往复,这样我们每次就会移动 次,就足够卡爆这个没加任何优化的方法。
怎么优化呢?我们可以修改每个询问的顺序,尽量让两个询问之间移动次数最少,这里说一种咋看有点玄学的方法,我们把序列分成 个块,如果两个点的左端点不在同一块,左端点小的放前面,如果左端点所在块相同,那就比较右端点,右端点小的排前面。
可以证明,最坏复杂度为 。我有一个绝妙的证明方法,可惜这里的空白太小了(分明是作者不会)。
还能优化?没错,我们修改一下排序规则,如果两个点的左端点不在同一块,左端点小的放前面,如果左端点所在块相同,那就比较右端点,如果当前块编号为奇数,右端点小的放前面,否则右端点大的放前面。还想问为什么?应该不需要我放那句话了吧。
小B 有一个长为 的整数序列 ,值域为 。
他一共有 个询问,每个询问给定一个区间 ,求:
其中 表示数字 在 中的出现次数。
小B请你帮助他回答询问。
莫队板子题。问题在于该如何修改呢?其实很简单,当我们将某个点加入当前区间时,设这个点所表示的值在当前区间的值为 ,那么答案会增加 ,当我们将某个点从当前区间删除时,设这个点所表示的值在当前区间的值为 ,那么答案会减少 。
1 |
|
作为一个生活散漫的人,小 Z 每天早上都要耗费很久从一堆五颜六色的袜子中找出一双来穿。终于有一天,小 Z 再也无法忍受这恼人的找袜子过程,于是他决定听天由命……
具体来说,小 Z 把这 只袜子从 1 到 编号,然后从编号 到 的袜子中随机选出两只来穿。尽管小 Z 并不在意两只袜子是不是完整的一双,他却很在意袜子的颜色,毕竟穿两只不同色的袜子会很尴尬。
你的任务便是告诉小 Z,他有多大的概率抽到两只颜色相同的袜子。当然,小 Z 希望这个概率尽量高,所以他可能会询问多个 以方便自己选择。
其实没那么难,设当前区间编号为 的袜子有 双,根据概率论和一点数学,答案是:
。现在会做了吧,就是上一题加一点东西。
1 |
|
如题,给定一棵有根多叉树,请求出指定两个点直接最近的公共祖先。
这次我们要使用的知识点是 和并查集,这个 是离线的,我们要先把每个点的每一个要跟它求 的点给记录下来,接下来用 跑这么个流程:
等等,你是不是蒙圈了?我们先放张图:
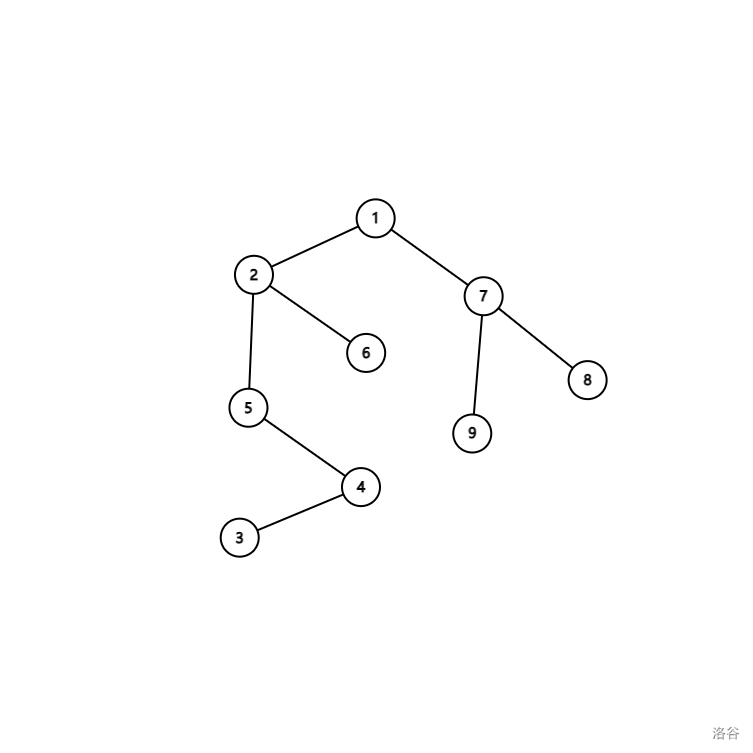
假设我们要求 。
我们在这张图上模拟一下并查集中的过程:
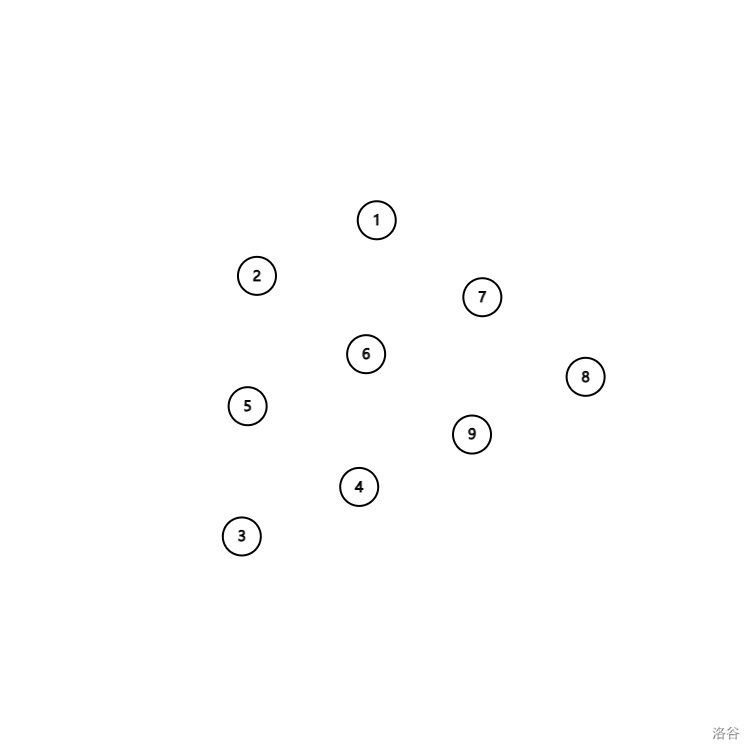
首先,一切还是一盘散沙:
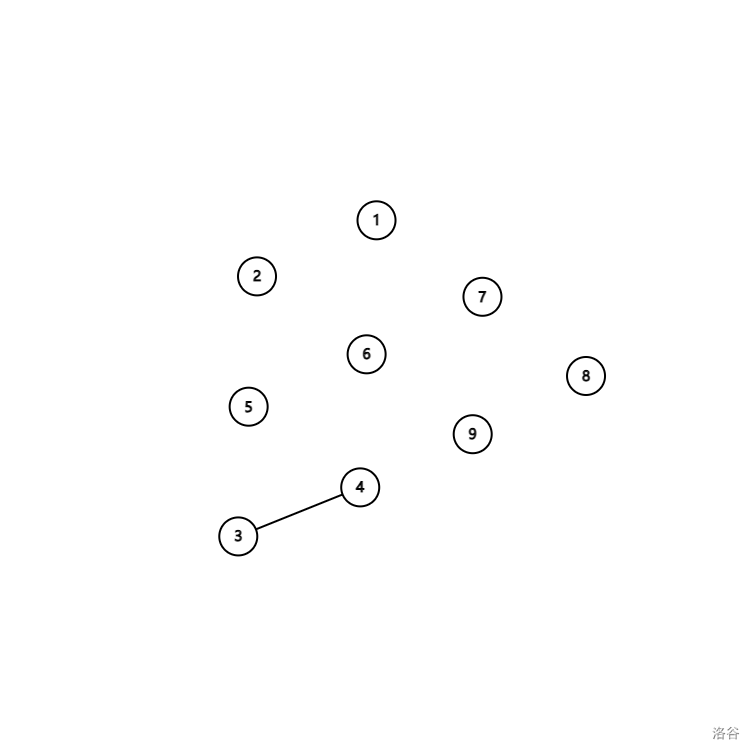
接下来, 和它的父节点 合并起来了,由于与 它相关联的 还没访问,此时无法更新任何答案:
接着又是 以及 ,都无法更新答案:
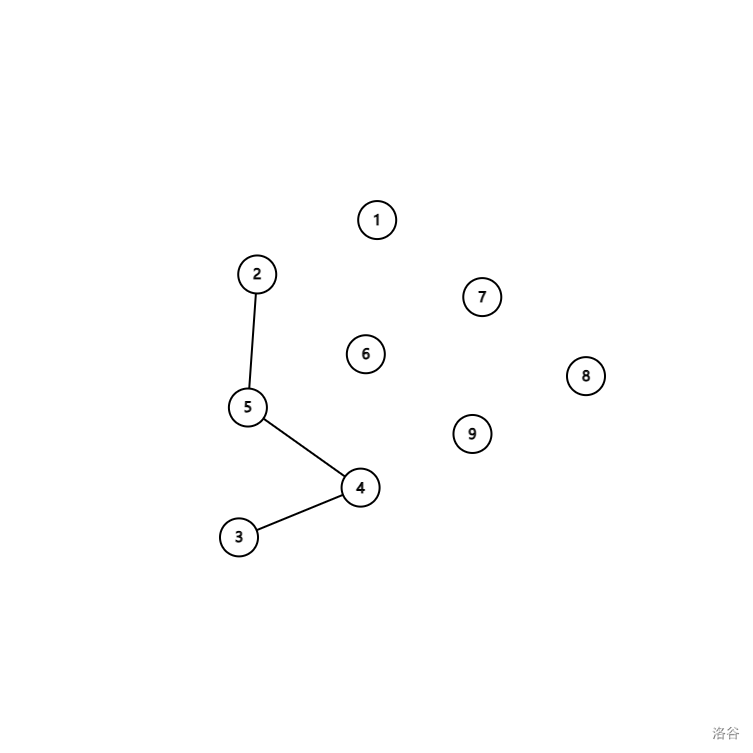
注意了!!!此处敲黑板!!!此时我们访问到 的另一个子节点 ,此时我们便发现, 已被访问,于是答案是 !!!
后面的无用功就不放了。
于是,我们就发现了,其实我们就是把点按 序不断合并,当两个点要合并在一起时,此时的祖先便是答案,就像这样:
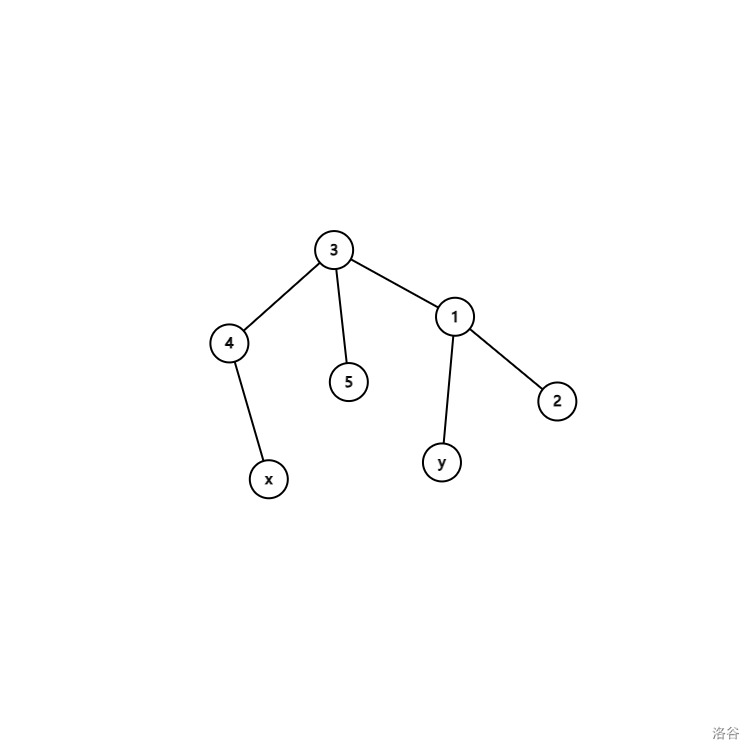
和 便是要求 的两个点,它们现在刚好就合并到一起,显然只有到它们的公共祖先它们才会合并在一起,再由于回溯时是从深到低,所以第一次合并在一起时一定是到 了。
1 |
|
给定 个模式串 和一个文本串 ,求有多少个不同的模式串在文本串里出现过。
两个模式串不同当且仅当他们编号不同。
我们可以将所有模式串存进 树中,像这样:
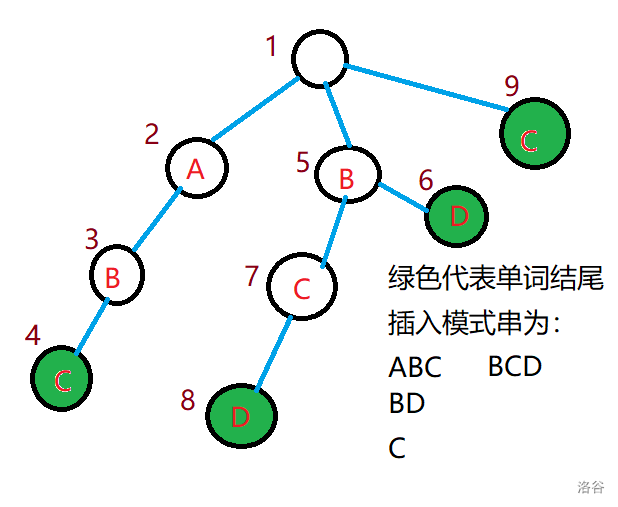
此时如果我们朴素地查找,那显然会超时,因此我们可以使用类似 算法的思想,对于每个点都创建一个 指针,表示与当前节点表示的字符串在 树中出他自己外的后缀最长的那个所在位置,就拿图来举例吧,对于节点 $ 4$ 他的表示的字符串为 ,它的除它自己外的后缀有 ,,在 中它们都存在,于是我们取最长的 ,它在 $ 7$ 号节点,所以 。
那怎么求 呢?这个我们可以用广搜来实现,毕竟一个点的 显然不会比这个点深。那么一个点的 就是它父亲的 对应的当前节点的字符,也就是说若设 为当前节点, 为它的父节点, 为 这个节点存的字符,那么就有 。特别地,如果 还没建立我们可以让 直接等于它的 值。
有了 后,一切就好办了,只需要将要匹配的文本串在 中查找,每到一个节点就不断跳 更新答案,毕竟当前节点能匹配上,那它的后缀自然能匹配上嘛。
一定不要重复记录一个点的贡献。
1 |
|
给定 个模式串 和一个文本串 ,求有多少个不同的模式串在文本串里出现过。
两个模式串不同当且仅当他们编号不同。
这题跟前一题咋看区别并不大,很容易想到用数组记录答案,每匹配上一次就更新答案,但是这样做由于一个点会被访问不止一次,时间复杂度无法接受,因此需要优化。我们来分析一下,就拿前面那张图举例:
我们会发现当到达 $ 4$ 时,我们会接着一连更新 $ 4,7,9$,到 $ 7$ 时又会更新一遍 $ 7,9$。很显然,问题就是出在这里,我们每个点不断被一次一次地更新,导致时间复杂度过大。因此,我们需要找到一种方法能够一次性统计一个点的答案。
我们可以把每个 当作一条边建图,易证这是一个 ,我们可以不用不断跳 只需要标记当前点,再跑一遍拓扑排序,在拓扑排序的同时进行递推,这样每个点只会被更新一次,大大降低了复杂度。
1 |
|
割点是怎么回事呢?是这样的,如果图中的某一个点被删掉后图的最大连通子图数量变少了,也就是说那个点所在的最大连通子图被分成了多个最大连通子图那么这个点就是图的割点。
知道概念后,又该怎么求呢。
首先,我们求出节点的 序,这用 就可以做到,同时,在 时,维护 表示一个点在不经过在自己在 树中的父节点能到达的 序最小的节点的 ,如果节点 存在一个它在 树中的子节点 使得 ,那么节点 就是一个割点,为什么呢?其实很简单,毕竟如果 点不经过 点就到不了前面 序更小的 的祖先,那就说明去掉 节点后 就与前面的不连通了。同时,还有一种情况需要讨论,那就是当 是他所在 树的根时,只要有两个及以上的去掉 就无法互相连通的子节点,拿他也是割点。
接下来讲求 的方法,先给方法。若 是 的 树子节点,那 ,否则 。证明?很可惜我现在还不会。
1 |
|
割边和割点差不多,不过点变成了边。
总体区别与割点并不多,首先便是判断时变成了 ,为什么呢?因为 到 的边是唯一的,所以从 出发不经过 结点就相当于不走 这条边,所以如果去掉该边 连 都连不上,那就不行了。其次便是不用考虑是否是根。
1 |
|
十分朴素的做法,设 表示第 天学习第 种算法 天的方案数。那么对于 ,自然就可得:
对于 (),可得:
显然, 那一维可以省去,再加上前缀和优化,时间复杂度 ,空间复杂度 。
1 |
|
得分:50pts。
AC 代码,设 表示第 天学习第 种算法的方案数,接着,枚举学习的天数,得:
接着,我们进行优化,用 表示 ,用 表示 ,边 dp 边计算这两个,于是可得 。最后,我们可以把 这一维压掉,注意,取模时减法要加上模数再取模。
1 |
|
看到这道题,原以为是暴力枚举,一看题目难度和数据范围就明白了,这是道数学题(其实我是看标签知道的)。
好了,言归正传。
1 |
|
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
1 | $ hexo new "My New Post" |
More info: Writing
1 | $ hexo server |
More info: Server
1 | $ hexo generate |
More info: Generating
1 | $ hexo deploy |
More info: Deployment